

System programming concepts in distributed systems
File concept review
File is a higher level of abstraction. In UNIX like system, we can say that everything is a file.
A File contains:
- timestamps: creation, read, write, header.
- File type
- ownership
- Access control list: who man access in what mode.
- Reference count: number of directories containing this file. When 0, delete this file.
Like I said, everything is a file. So directory is just a special case of file, too. It is a file containing the meta-data about files in that directory and pointers(on disk) to those files.
We open and close a file with file descriptors with mode (r read, w write, x executable).
Distributed file system
Similar to other concepts, distributed file system should also ensures:
- Transparency: clients access file as if it were accessing local files.
- Support concurrent clients: multiple clients can read/write the file concurrently.
- Replication: fault-tolerance, not lose file when one serve is down. It also has to ensure one-copy semantics, which means when a file is replicate. there is no difference from the file having exactly 1 replica for clients.
It is also important to ensure everyone has the proper right to access files, when involves authentication. Two ways to do this:
- Access Control list: list of allowed users and their modes, per file
- Capability Lists: list of allowed files and their mode, per user.
Navigation of two popular Distributed file systems: NFS & AFS
Network File System (NFS)
A general structure of NFS is:
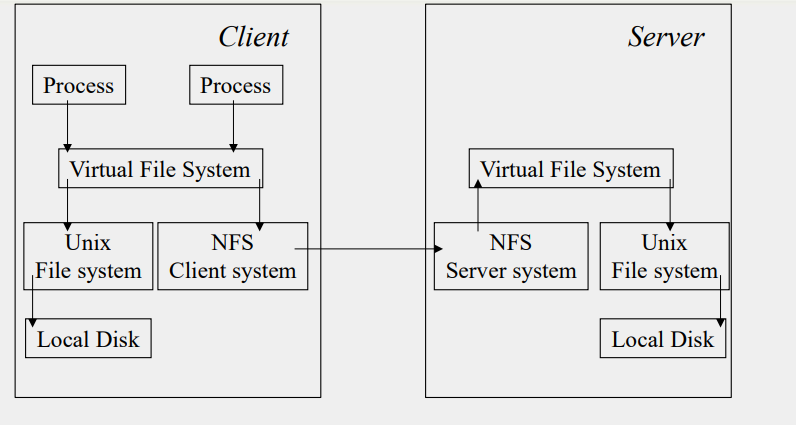
Client:
For a client, if a file exist on local system, use UNIX local system, if not, use NFS client system to navigate virtual file system on server, which will search on its own local disk.
It contains data structure of v-node, which is similar to i-node in UNIX. If target file is local, v-node points to local disk i-node. If not, v-node contains address of remote NFS server.
Client Caching: store some of the recently-accessed blocks in memory, have to ensure local cache copy is consistent with server copy by checking modified time and setting up freshness interval.
Example: If client sets up freshness interval = 4s, a client finds that a data block it is storing has two timestamps: last validated timestamp=12345 s, and last modified timestamp=12340 s. At the same time, the server’s last modified timestamp=12346 s. If the client clock currently reads 12350 s, since 12345 + 4 < 12350, so data block is no more fresh and need to be validated. And since 12340 $\neq$ 12346, client fetch the block from the server as the server has latest copy.
Server:
Server caching: store some of the recently-accessed blocks in memory, because most of program written by human have locality of access, beneficial for read.
Delayed write: write in memory and flush to disk periodically, this is fast but inconsistent.
Andrew File System (AFS)
Design principles:
- whole file serving (not in blocks)
- whole file caching (permanent cache, survives reboots), a type of delayed write.
Motivation (validated assumption) for the principles:
- Most file accesses are by a single user
- Most files are small
- File reads much more often than writes, and typically sequential.
- Most of the time, cache is large enough to support
Clients system is known as Venus service, server system is known as Vice.
Since for read and write, AFS is operating on a whole file level, read/write are optimistic. When sending a file from vice to venus, it is accompanied with a callback promise, which promise that if another client modifies then closes the file. In this way, it prevents concurrent modifications/writes.
- 本文作者: Yu Wan
- 本文链接: https://cyanh1ll.github.io/2021/01/18/distributed-file-system/
- 版权声明: CYANH1LL